
Quand on parle de Modern Data Stack, les PME et les startups ont tendance à ne pas se sentir concernées.
Pourtant, des grandes entreprises aux startups en phase de démarrage, toutes les entreprises collectent des données, ce peu importe le secteur d’activités : retail, e-commerce, éducation, tourisme, finances… Et elles partagent un défi commun : comment exploiter efficacement et intelligemment les données ? Dans un monde où les experts considèrent les données comme la ressource la plus précieuse de l’économie numérique, ceux qui parviennent à exploiter la valeur des données prennent sans aucun doute une longueur d’avance sur la concurrence.
Néanmoins, beaucoup d’entreprises, notamment les startups et les PME, considèrent encore que l’exploitation des données n’est pas encore une priorité, le manque de ressources financières étant l’obstacle n°1 pour devenir “data-driven”, surtout en cette période de crise.
L’exploitation des données est pourtant primordiale, et deviendra même indispensable à l’avenir pour prospérer dans un monde hyper concurrentiel.
Il viendra donc un moment où vous devrez pouvoir analyser vos ventes, votre CA, l’impact de vos actions marketing, etc. afin de prendre des décisions stratégiques pour rester en tête du peloton. Pour se faire, une Modern Data Stack est la brique essentielle pour collecter des données auprès de différentes sources (réseaux sociaux, Google Analytics, CRM, etc.), les intégrer dans une plateforme centralisée et créer des rapports et des tableaux de bord.
Les solutions les plus évidentes qui nous viennent à l’esprit pour faire face à ces défis nécessitent très souvent une large gamme d’outils, chacun de ses outils réalisant un seul ensemble de tâches. Cela nécessite généralement une équipe de data engineers pour apprendre, construire, exploiter et surveiller les pipelines de données mises en place ce qui crée des risques de défaillance à plusieurs points ainsi qu’un looooong process pour (enfin) obtenir les données dans un format exploitable.
Résultat ? Les petites entreprises qui n’ont pas les ressources ou les fonds nécessaire pour embaucher une équipe technique pour construire et gérer une data stack passent à côté d’une mine d’or d’informations.
Et pourtant, devenir data-driven n’est pas réservé aux grandes entreprises disposant de budgets importants. Même avec des ressources très limitées, il est tout à fait possible de démarrer la valorisation des données, à commencer par la mise en place d’une modern data stack à (tout) petit prix. Explications.
La modern data stack, c’est quoi ?
Une modern data stack (ou MDS) est un ensemble d’outils regroupés autour d’un data warehouse et stocké sur une plateforme cloud. Elle est le socle de base pour toute entreprise qui souhaite se lancer dans l’exploitation de ses données et devenir data-driven.
Une modern data stack se compose généralement de quatre étapes :
- Collecte (ou ingestion) : cette étape consiste à collecter les données à partir de diverses sources de données (bases de données, web, API…)
- Chargement : une fois les données collectées, celles-ci sont chargées et centralisées dans le data warehouse
- Transformation : ensuite, un outil de transformation est utilisé pour nettoyer les données brutes et appliquer la logique métier afin de calculer les KPI souhaités
- Analyse : enfin, vos collaborateurs vont pouvoir utiliser les données pour créer des rapports et obtenir des insights pertinents à l’aide d’outils de BI et de visualisation.
“Mais comment mettre en place une modern data stack avec mon mini budget ?” On vous explique tout, étape par étape👇🏼
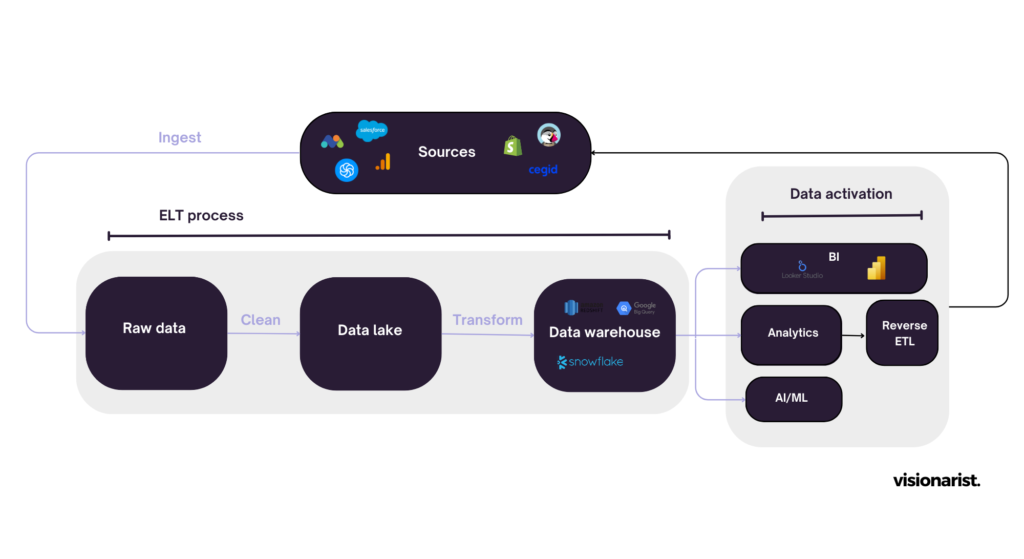
Le data warehouse pour centraliser toutes vos données
Le data warehouse est un système centralisé où toutes les données de l’entreprise, provenant de sources multiples, sont stockées de manière organisée et structurée. Il vous permet de regrouper toutes vos données, peu importe le volume et de tirer des informations grâce à des tableaux de bord analytiques, des rapports opérationnels ou des analyses avancées pour tous vos collaborateurs.
Il existe plusieurs solutions sur le marché : BigQuery, Snowflake, Azure ou encore Redshift (entre autres).
BigQuery est l’espace de stockage entièrement géré par Google Cloud. Il est sans serveur (ne nécessite pas de provisionnement ou de gestion préalables du matériel), hautement évolutif (interrogez de grands ensembles de données en quelques secondes) et économique (vous ne payez que ce que vous utilisez), conçu pour la flexibilité de l’entreprise. Il est donc idéal pour les PME et les startups.
BigQuery est très simple à configurer et peut être accédé via la console Google Cloud, sans compétence technique particulière. Il est activé automatiquement dès que vous créez un compte et un projet.
Avantage non négligeable : Google Cloud offre 1 To de requêtes par mois et 10 Go de stockage par mois gratuitement, ce qui est largement suffisant si vous commencez tout juste l’aventure dans l’exploitation des données.
Si vous êtes une startup, vous pouvez également postuler au programme Cloud Google for startups : cela vous permet d’obtenir un certain nombre d’avantages et notamment : jusqu’à 200 000 $ de crédits (jusqu’à 350 000 $ pour les startup d’IA) pendant deux ans, d’une formation technique, d’une assistance commerciale et d’offres valables sur divers produits et services Google.
L’ELT pour collecter et charger vos données dans le data warehouse
Maintenant que vous avez votre data warehouse en place, vous avez besoin d’un outil de collecte pour extraire les données brutes de différentes sources et les charger dans votre data warehouse pour toutes les centraliser et les stocker à un seul et même endroit.
Il existe plusieurs ETL sur le marché, parmi les plus connus : Stitch, Fivetran et Airbyte. Ces outils ont créé des connecteurs vers de nombreuses sources de données (Salesforce, Shopify, Google Analytics, Facebook, etc.), ce qui vous permet de collecter et charger automatiquement toutes vos données dans votre data warehouse en quelques minutes. C’est plutôt simple et accessible aux entreprises qui ne disposent pas de profils techniques en interne mais qui souhaitent tout de même accéder rapidement à leurs données et se concentrer sur les usages de la data.
Cependant, tous ces outils sont payants avec des méthodes de calcul du pricing qui peuvent varier. En général, la structure de tarification est basée sur le nombre de lignes.
Il existe également des solutions gratuites mais qui nécessite un peu plus de compétences techniques : les frameworks open-source qui permettent d’extraire les données de différentes sources et de les charger dans n’importe quelle destination. Le code de ces frameworks est ouvert et peut être utilisé par n’importe qui pour ses propres projets. Il vous faudra par contre :
- une solution pour stocker le code, des ressources de calcul pour exécuter le code permettant d’extraire et de charger les données de vos sources vers votre destination ;
- Un planificateur pour déclencher chacune des exécutions.
Si vous êtes une PME ou une startup, on vous conseille plutôt de démarrer avec un outil simple d’utilisation, vous permettant d’accéder à des centaines de connecteurs pouvant être configurés en quelques minutes seulement et ne nécessitant aucune compétence technique particulière. Il ne sera. pas totalement gratuit mais vous fera gagner du temps, et générera par conséquent un meilleur ROI.
Transformer vos données en KPI métiers
Une fois les données brutes chargées dans votre data warehouse, elles sont prêtes à être transformées. La transformation consiste à appliquer une série de règles ou de fonctions à vos données brutes : renommage de colonnes, fusion de plusieurs tables et agrégation de données.
En termes d’outil, on vous conseille DBT (Data Build Tools) : il s’agit d’un outil en ligne de commande qui permet notamment aux data engineers et aux data analysts de transformer les données dans le data warehouse. Concrètement, ils écrivent du code en SQL. DBT est open-source, son utilisation est donc gratuite mais nécessite tout de même certaines compétences techniques.
Débloquer le potentiel de vos données
Une fois toute cette brique technique installée, vos collaborateurs peuvent enfin accéder, analyser et utiliser les données par le biais de tableaux de bord ou de rapports pour prendre des décisions plus éclairées, d’analytics plus poussés ou encore de machine learning ou IA.
Google Cloud dispose d’un outil de visualisation des données totalement gratuit : Looker Studio. Il vous permet de transformer vos données en de jolis tableaux de bords, entièrement personnalisables.Looker Studio permet à vos collaborateurs de créer et de partager des insights pertinents en un rien de temps. Ils pourront facilement croiser de toutes vos sources et calculer des KPI précis. Pour les débutants, Google Studio propose également des modèles pour vous aider à démarrer.
Tous vos tableaux de bord peuvent ensuite être partagés à l’ensemble de l’entreprise, à vos clients ou encore à vos investisseurs !
Vous pouvez également utiliser Metabase, Tableau ou encore Power BI.
Et voilà, vous êtes prêt à créer vos premiers pipelines qui collectent, transforment et stockent vos données pour en tirer le meilleur parti.
Ce guide vous a donné un rapide aperçu des outils abordables que vous pouvez utiliser pour démarrer. Il va sans dire que la stack data que vous construirez et le choix des outils dépendra également de vos objectifs et de vos cas d’usages.
Au fur et à mesure que les volumes de données grandissent, il sera également nécessaire de développer des implémentations personnalisées, et donc d’utiliser des outils plus avancés ou de faire appel à des data engineers.
Bookez votre expertise data en moins de 5 minutes avec Visionarist
Implémenter une Modern Data Stack pour devenir data-driven est accessible à toutes les entreprises, même les plus petites ; même si vous avez peu de volume de données, oui oui.
Visionarist accompagne les PME et les startups dans la création de leur modern data stack rapidement et simplement.
Bookez un data engineer pour vous accompagner ou contactez-nous pour en discuter ❤️